The threat of climate change to agricultural production is significant, but for perennial crops in developing countries, the risks have new complications. In my latest study, “Confounding Adaptation in Perennial Climate Damages: A Unified Statistical Approach for Brazilian Coffee,” I uncover the alarming, yet previously unestimated risks affecting the Brazilian coffee industry.
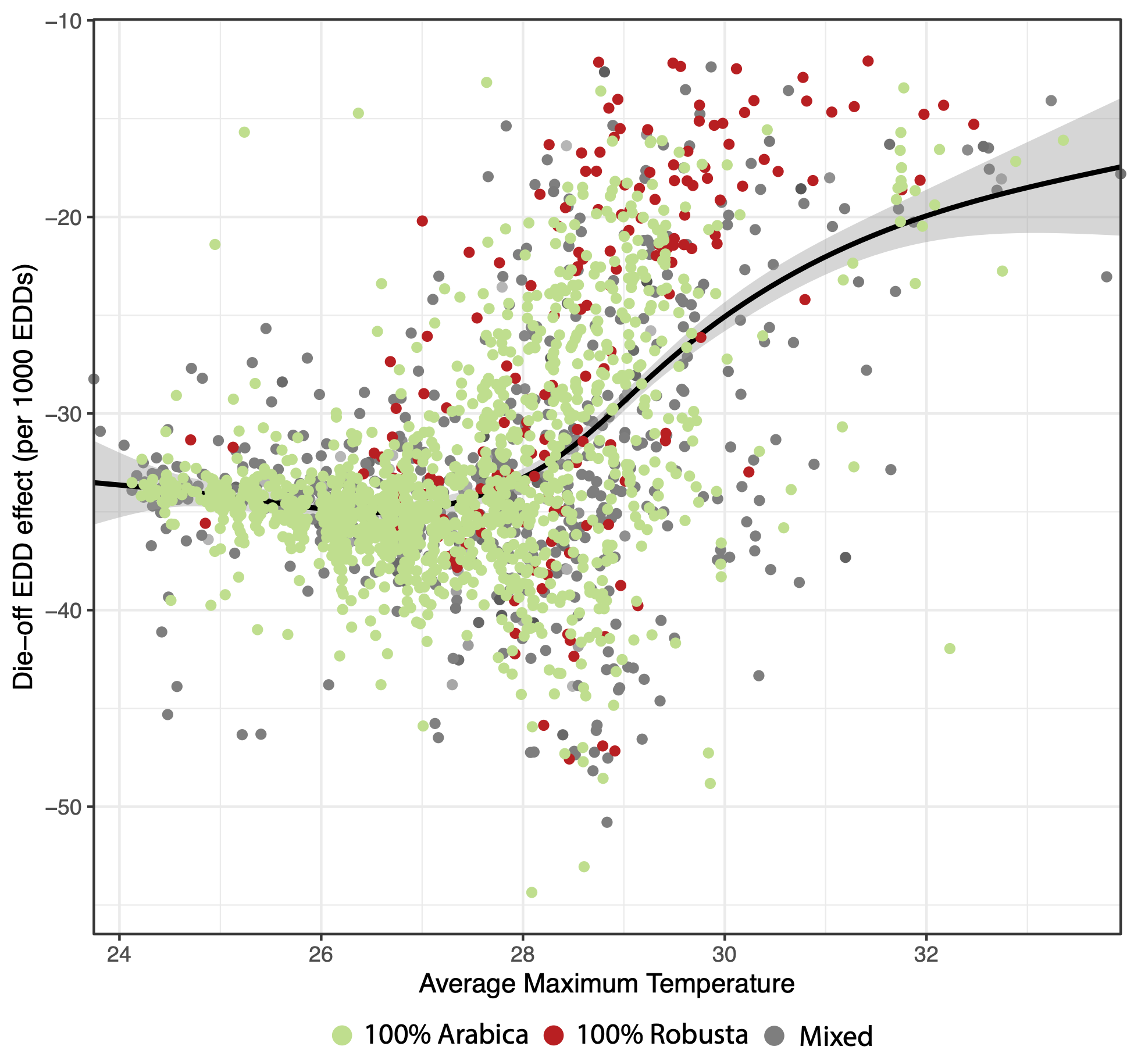
Misreported perennial yields and crop management decisions can significantly impact our understanding of these risks. The study reveals that extreme temperatures do reduce yields – but they also shrink the reported harvest area due to plant death and farmers’ selective harvesting. In other words, the actual damage from extreme temperatures on coffee production is twice as severe as effects recorded on reported yields.
In the study, I’ve developed a framework that merges perennial supply and statistical yield literature to distinguish the effects of management decisions. The process unearthed a direct impact of temperatures on biophysical yields and a plant death effect. Together they support a detailed understanding of how prices, weather, and farmer adaptations interact in the realm of perennial crops – particularly crucial in developing economies.
This semester, I taught an amazing new version of a class on “Coupling Human to Natural Systems”. The goal of the class is to understand how social systems and environmental systems impact one another and co-evolve. To do so, the class provides a broad introduction to system dynamics, and the students get to develop their own group projects.
The resulting projects were excellent, with an analysis of real-world issues by developing sophisticated coupled models. Below are a summaries of a couple of the group projects.
Offshore Wind and North Atlantic Right Whales: Modeling an Uncertain Interaction
Authors: Lorren Ruscetta, Emma Korein & Laura Taylor
Abstract: Amidst the ambitious US goal to deploy 30 gigawatts of offshore wind energy by 2030, concerns about the environmental impact on marine life, particularly the North Atlantic right whale (NARW), a vulnerable species under the Endangered Species Act, have become prevalent. This study focuses on the proposed Ocean Wind 1 project off the coast of New Jersey and its potential impacts on NARW populations, balancing the deployment of 98 planned turbines with stakeholder support dynamics. Utilizing an integrated model that considers factors such as noise pollution, vessel collisions, artificial reef benefits, and stakeholder support, the research explores the influence of offshore wind infrastructure on NARW populations and the extent of the project’s realization. The model outcomes indicate that while NARW populations may not face significant decline due to the wind project, stakeholder support is sensitive to whale mortalities associated with turbine construction. Simulations predict that despite the initial aim, only 36 out of 98 turbines would be constructed due to stakeholder opposition following 1.6 NARW deaths. Sensitivity analyses further reveal the robustness of NARW populations under various scenarios but consistently suggest fewer turbines than anticipated will be erected, highlighting stakeholder perception as a crucial factor in determining the project’s scale. Consequently, the model provides policy insights and underscores the need for careful consideration of both marine conservation and stakeholder concerns in executing offshore wind projects.
Keywords: Offshore wind energy, North Atlantic right whale, stakeholder support, marine conservation, environmental impact modeling.
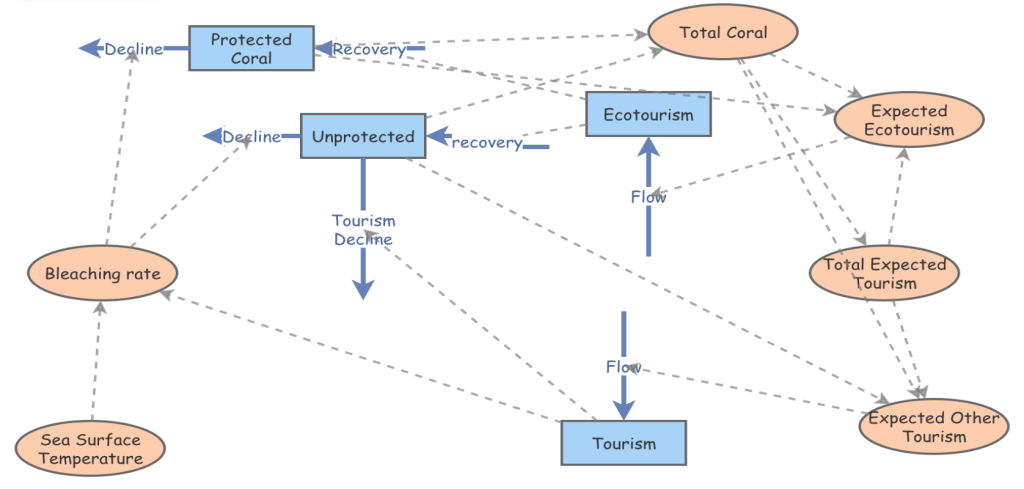
Impact of Ecotourism on Florida Keys Coral Reefs
Authors: Christina Marchak, Travis Pluck & Yuleny Gomez Rodriguez
Abstract: Coral reefs, such as those in the Florida Keys, offer critical ecosystem services and serve as a hub for tourism and ecotourism. However, they face threats from climate-related factors like rising sea surface temperatures (SST) leading to coral bleaching, and from socioeconomic activities. This paper explores the dynamics between ecotourism, SST, and coral reef health. A dynamic coupled system model is developed to analyze the impacts of human activities (ecotourism and normal tourism) on the health and cover of coral reefs, using the representative coral species Acropora palmata. The model integrates variables like tourism revenue, bleaching rate due to SST, and coral recovery rate. The study found that ecotourism and normal tourism, affected by SST, influence coral health and cover. Higher SST was linked to increased bleaching rates and reduced coral cover. Conversely, appropriate levels of ecotourism funding can mitigate these effects through conservation efforts such as coral seeding, creating a positive feedback loop for coral cover. The model revealed thresholds of coral decline that affect tourism and showed both declines and stabilization scenarios in the presence of varying levels of ecotourism intervention. The research provides critical insights for policymakers and stakeholders to consider the balance between tourism and coral conservation in the Florida Keys. It suggests that directing resources from ecotourism revenue towards restoration and conservation strategies may help sustain these vital ecosystems.
Climate change will affect all aspects of our lives and economies. As summers get hotter and storms stronger, it will undermine our ability to grow food, to have secure homes, and produce sustainable incomes. At the same time, stopping climate change will also have consequences for society. Our ability to compare the costs and benefits of climate action is crucial to making sound global decisions.
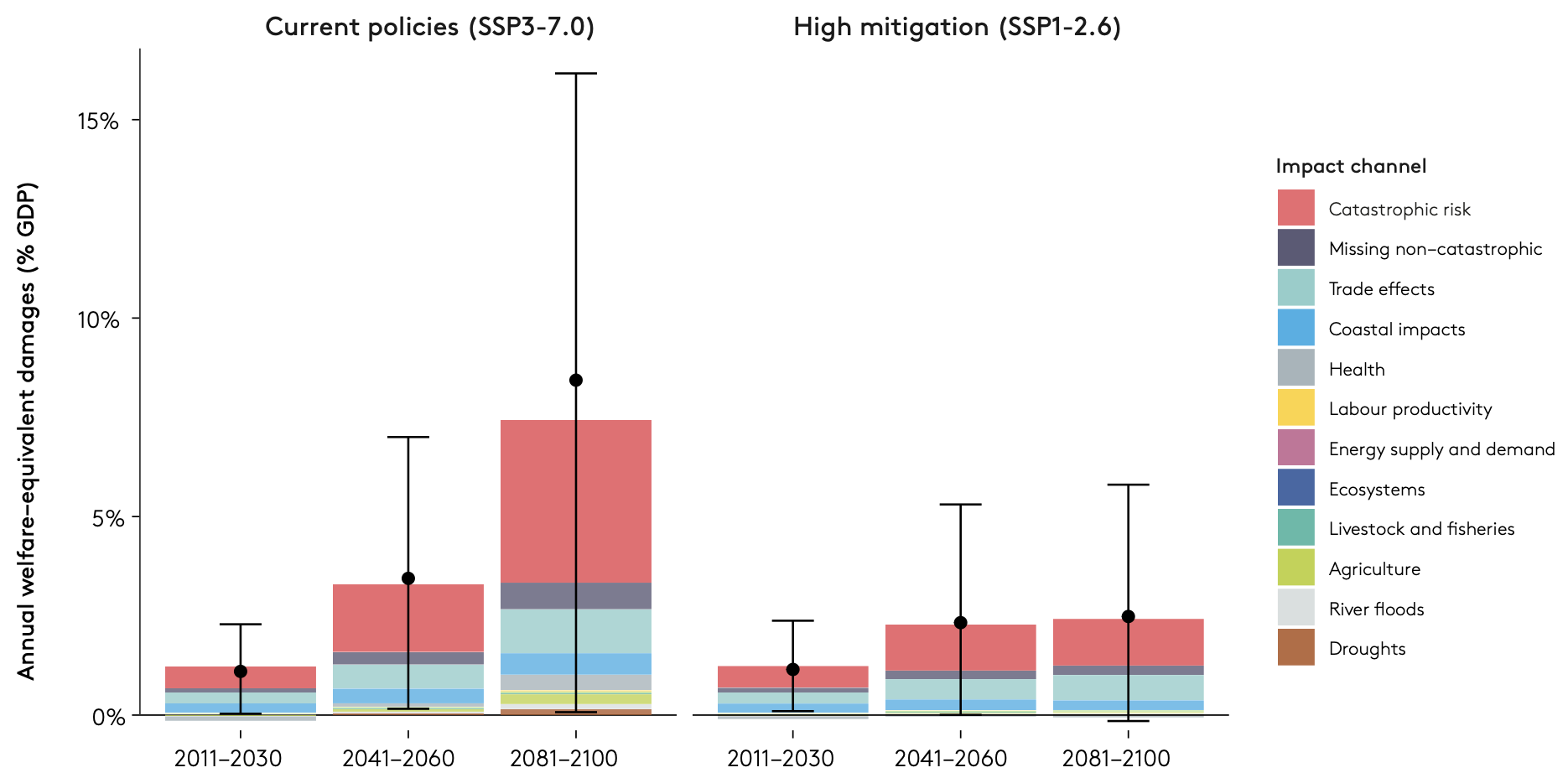
Earlier this month, I led a team to complete a comprehensive economic assessment of climate risks for the United Kingdom. The UK is a leader in shifting its economy toward Net Zero, and has years of experience understanding the costs of shifting to green energy. But it has not had a corresponding cost number for the impacts it can expect. Particularly since the UK cannot direct the actions of the rest of the emitting world, this numbers are important to know.
The big challenge in producing an estimate like this corralling results from many other studies into a consistent framework. Across the studies that have tried to do this before (for the US and the EU), we were able to produce perhaps the most comprehensive assessment of all, with impacts on everything from cows to coasts, from biodiversity to productivity.
FUND model
PESETA II-IV(2014-2020)
American Climate Prospectus (2015-2017)
Climate Impact Lab – DSCIM(2021-2022)
Temperature Binning Framework (2021)
CCRA3 Monetary valuation (2021)
UK Climate Costs Report (2022)
Windstorm
✔
✔
Wildfires
✔
Storms/floods
✔
✔
✔
✔
✔
Drought
✔
✔
✔
Coastal/SLR
✔
✔
✔
✔
✔
✔
✔
Crops
✔
✔
✔
✔
✔
Livestock
✔
Ecosystems
✔
✔
Forestry
✔
Fisheries
✔
✔
Mortality
✔
✔
✔
✔
✔
✔
✔
Morbidity
✔
✔
Energy
✔
✔
✔
✔
✔
✔
Labor
✔
✔
✔
✔
✔
Crime
✔
Recreation
✔
Trade Spillover
✔
✔
Catastrophic
✔
To jump to the conclusion, we find that the costs of unmitigated climate change (“current policies”) reach 7.4% of the UK’s GDP. And this is for one of the most un-vulnerable countries in the world. On the other hand, the costs for going to Net Zero are actually negative, once you account for the health co-benefits and the investment boost.
There is a lot more work to do to understand who is at risk and what they can do about it. But there is a lot to dig into in these results already. Our data is all available (link below), and I invite you to start digging!
Agriculture is going to be one of the sectors most disrupted by climate change. Our ability to produce food relies on a stable climate. Crops and management practices are carefully catered to local climate conditions, including the timing and intensity of rainfall, the length of growing seasons, and the complex biology of soil. Climate change is going to disrupt all of this, demanding new practices, new varietals, and for many regions, new sources of water or arable land.
Will farmers be able to adapt? Or are the details of effective farming too complicated, so that it will take decades to find the right new practices and seeds, by which time the climate will have changed again? This is a fundamental question for the future of food security globally and the livelihoods of millions of farmers.
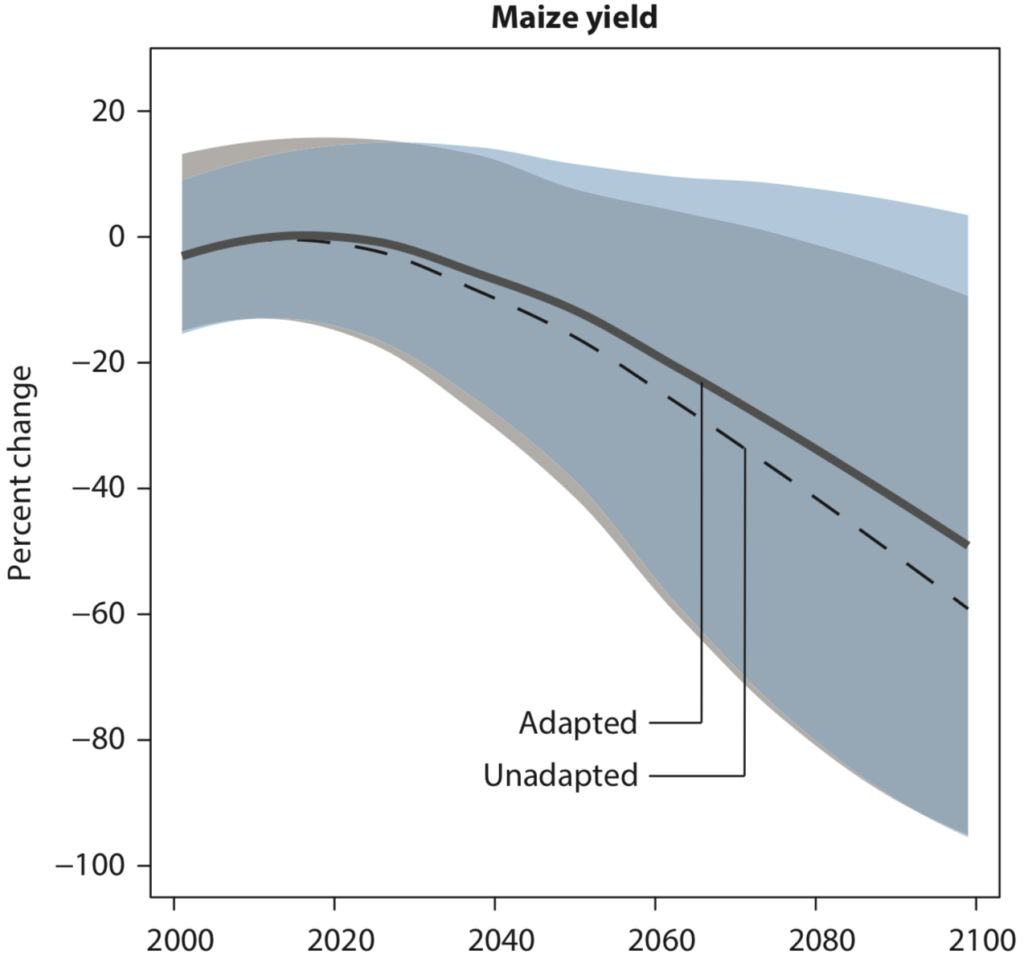
One piece of evidence comes from following the harmful effect of high temperatures on crops in the United States. Temperatures over 29 °C damage corn (maize), but this effect can be attenuated by irrigation. As a result, the damaging effect of high temperatures is observed to be much less in the extensively-irrigated US West than in the East. It has also been observed that the impact of high temperatures has slowly declined over the course of the historical yield record, from 1950 onward (Burke & Emerick, 2013). This is climate adaptation occurring as we watch!
So how quickly have farmers reduced the impact of high temperatures? Unfortunately, very slowly. Reducing the damages by 10% takes about 40 years. We modeled this effect across the next century, and whereas climate change would reduce yields by almost 60% by the end of the century (under business-as-usual), adaptation results in yields only being reduced by about 50%.
The loss in yields from climate change, with adaptation (solid) or without (dashed).
Clearly adaptation in the past cannot be a blueprint for adaptation in the future.
One of the most common stories about agriculture in the US is that it will just move north. If it’s too hot here, it will be just right in Canada. That will be bad for US farmers, but certainly not an existential threat to our ability to feed people in the future. But can agriculture find as fertile grounds north?
To answer this, I collaborated with Naresh Devineni, a hydrologist and Bayesian modeler. We developed a new model of the sensitivity of crops in the US to climate change, and a way to project crop switching into the future. The paper was recently published in Nature Communications.
The results suggest caution. Can crop-switching reduce the impacts of climate change? Yes, but 50% of the losses from climate change cannot be adapted away. Will many farmers have to change what they grow? A ton: To get the benefits we describe, over 50% of farmers will have to change what they grow.
Why can’t crop-switching remove all of the impacts of climate change? Almost everywhere, the value of the land for planting any of the crops we model will fall. In fact, in our model about 5% of current agricultural land will be left fallow by 2070, because any crop will cost more than it would generate in profit.
The change in profits by 2070 for land under its most productive use.
NPR Marketplace recently put these results in the broader context of risks from climate change. Listen to the piece to learn more:
From Bloomberg Green: Life and Death in our Hot Future Will be Shaped by Today’s Income Inequality
The Climate Impact Lab just got a great write-up for our work on the risk of mortality under climate change in Bloomberg Green. There are a bunch of excellent dynamic visualizations that dig into the data.
There are two big messages here. The first is that poor people are going to get hammered by climate change, with some areas experiencing deathrates from the additional heat that are greater than the combined global rates for heart disease, stroke, all forms of cancer, all forms of infectious disease death, and all forms of death from injury.
The other is that we can use this information to start to estimate the total cost of climate change to society at large, because it gives us a lower-bound. Just the effect of additional mortality costs society about $22 per ton of CO2. That’s already more than the total social cost used by the Trump administration and half way to the total cost used by the Obama administration.
Take a look at the summary write-up of the research behind the Bloomberg article, and look forward to the reports that we are going to produce on the effects of climate change on labor productivity, agriculture, energy demand, and coastal impacts.
There is a rising tide of people who want to get involved in climate econometrics, dissipating against the shallows of unfinished research ideas, and spinning like weather vanes trying in vain to understand weather. Well, no longer! I would like to introduce climateestimate.net!
ClimateEstimate.net is an introduction to the secrets of using climate data, generating weather panels, choosing specifications, and getting results. Think of it like a practical complement to Solomon Hsiang’s SHCIT list: http://www.g-feed.com/2018/11/the-shcit-list.html
The tutorial is still new, and we would love your feedback and suggestions. And you are welcome to get involved and help us extend the tutorial (there’s an ocean still to cover!).
The highest good is like water. Water gives life to the ten thousand things and does not strive. It flows in places men reject and so is like the Tao.
– Tao Te Ching (Lao Tzu)
Water is such a fascinating resource because it’s at the center of things: absolutely necessary, but generally given no value. This the fundamental enigma that has motivated a huge growth in the study of “water-energy-food systems” (WEF systems or nexus). But the WEF nexus are also defined to dodge the central problems of water.
The first dodge is by framing water as an equal partner with energy and food. As I’ve written before, water plays a very different role than energy or food: energy and food are completely dependent on water, not so much on each other. WEF systems should better be called “Greater Water Systems”.
The second dodge is a common avoidance of the fundamental decisions-making build into water systems. Water availability isn’t really a physical fact of nature: it depends on human decisions. Water grows scarce when we demand more than the natural system can provide. And in most areas of the world now, water supply is the result of our investments in reservoirs, canals, treatment and reuse systems. WEF systems have no static elements; it is constantly being created by us.
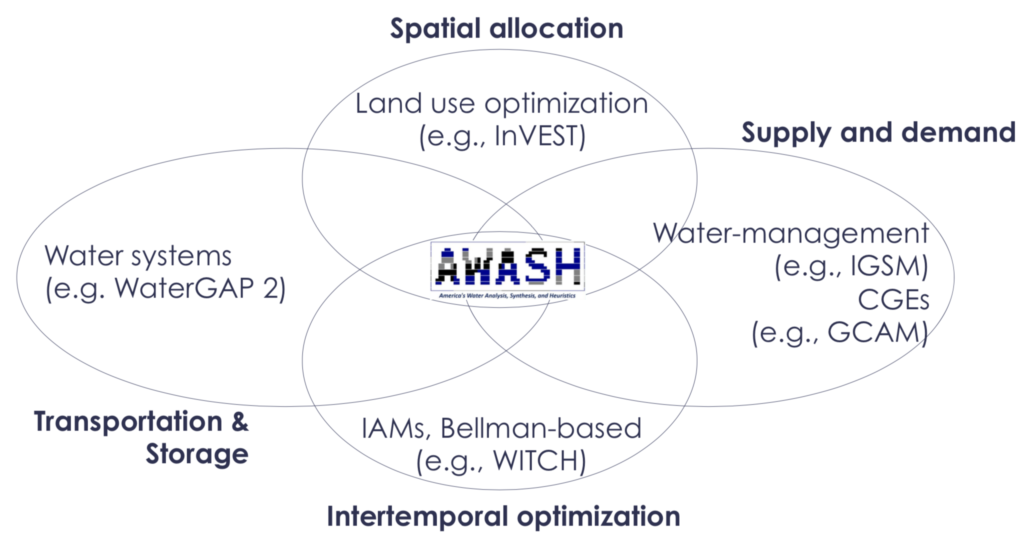
A full understanding of the WEF nexus requires an integrated approach, which makes decisions about water use and infrastructure, based on how we can ensure the most beneficial use of water for ourselves and the environment. I presented on these ideas at the 1st International Conference on Water Security, using the AWASH model to understand long-term investment decisions around reservoirs.
The insights from that work were published this week in the new journal Water Security. Take a look:
Our paper says that even though we cannot yet quantify these risks, we should be planning for them. Even if the worst scenarios are unlikely to happen, leaving them out of our discussions with policy-makers is the same as claiming that their risk is zero, which is not right either. Governments regularly plan for international security scenarios that only have a 1-in-10,000 chance of happening, and we should treat the worst risks of climate change the same way.
Dividing an elephant in half does not make two small elephants. It makes one mess.
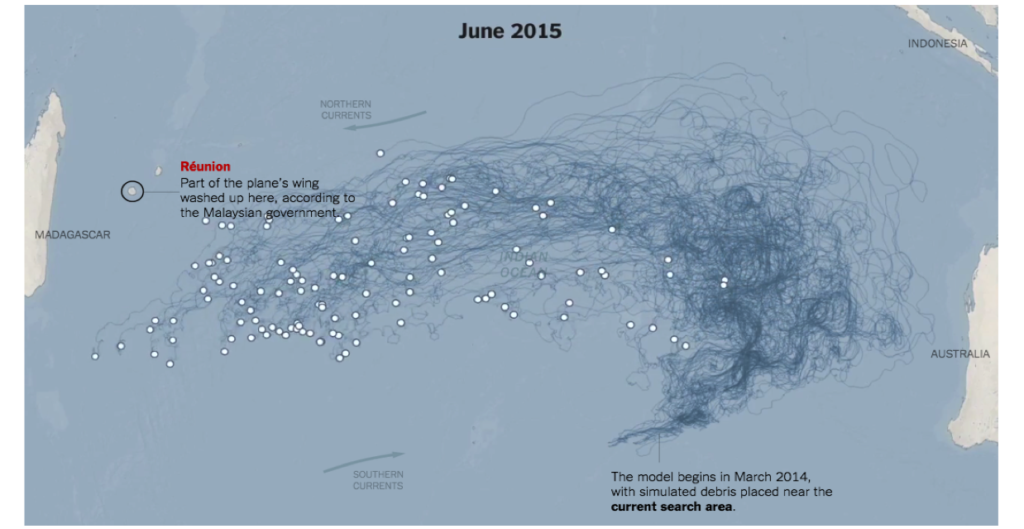
The same is true of our oceans. Modern management of the natural environment is all about dividing up elephants, assigning the halves to different owners, and blinding ourselves to the activities beyond our halves. But just as with elephants, pieces of an ocean depend on each other: fish and currents do not respect national boundaries.
To study this, we used the same model used to study how debris from the Malaysia Airlines Flight 370 crash ended up halfway around the world:
Instead of looking at airplane debris, we looked at fish spawn. Most marine species spend a stage of their lives as plankton, either in the form of floating eggs or microscopic larvae. They can travel huge distances as they float with the currents, sometimes over the course of several months. We can use those journeys to identify the original spawning grounds of the adult fish that are eventually caught.
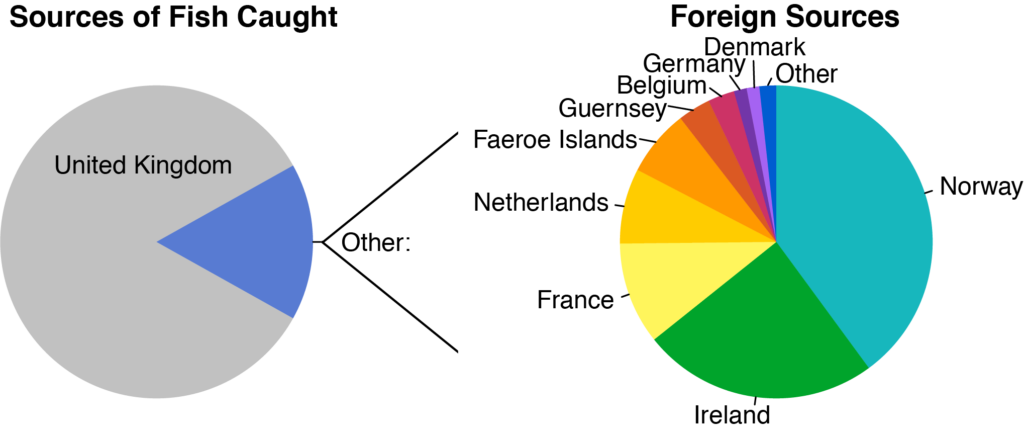
These connections are important, because they mean that your national fisheries depend upon neighboring countries. Spawning regions are highly sensitive, and if your national neighbors fail to protect them, the fish in your country can disappear. A country like the UK depends upon plenty of other countries for its many species.
Finally, this is not just an issue for the fishing sector. We also looked at food security and jobs. People around the world depend on the careful environmental management of their neighbors, and it is time we recognized this elephant as a whole.
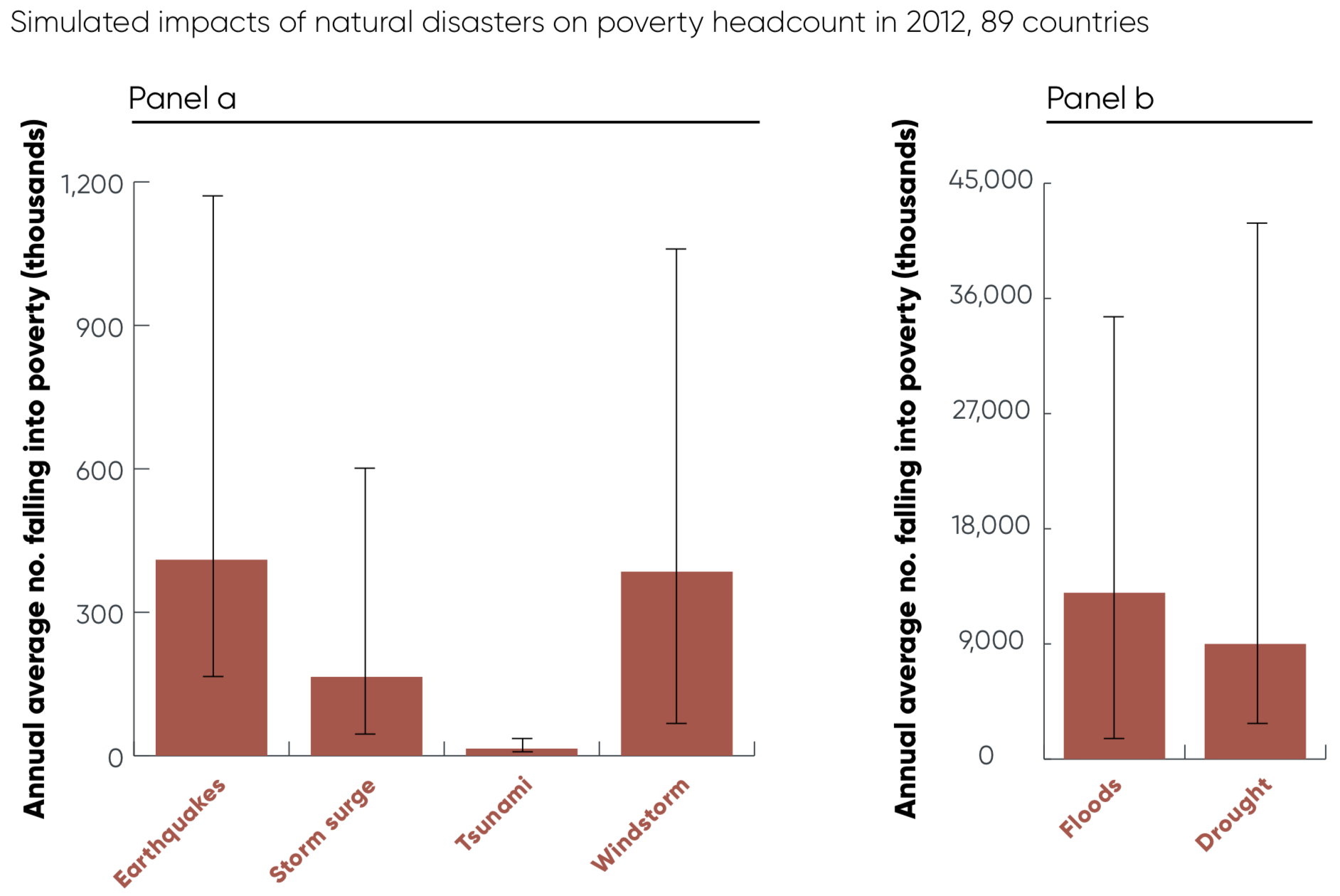
From “Unbreakable”: Estimated people driven into poverty annually by natural disasters.
I think it’s an amazing bit of modeling to be able to relate natural events to the excruciatingly chaotic process we call “falling into poverty”. But it’s the scale of the two sides of the graph that blows me away. On the left, earthquakes, storm surge, tsunamis, and windstorms all together account for about 1 million people falling into poverty every year. On the right, floods account for 10x as many, and droughts account for an additional 8x as many.
The reason is that floods and droughts are naturally huge events– covering large areas and affecting millions of people– every time they occur. The second is that they occur all the time.
This gets at the importance of water. Most of the researchers I know don’t spend much time thinking about water. They know it’s important, but in a way that’s so commonplace as to be invisible. We just said that 18 million people fall into poverty each year from floods and droughts; in 2015 there were 736 million people in poverty total. That means that if we magically got everyone out of poverty today, in 41 years, there would have already been 736 million new instances of poverty from floods and drought alone. Water is about enough to explain the stubbornness of extreme poverty all on its own.
James Rising is a researcher at the School of Marine Science & Policy at the University of Delaware. Dr. Rising studies the economics of the environment, with an emphasis on risks from climate change and opportunities for better policy in the food system.