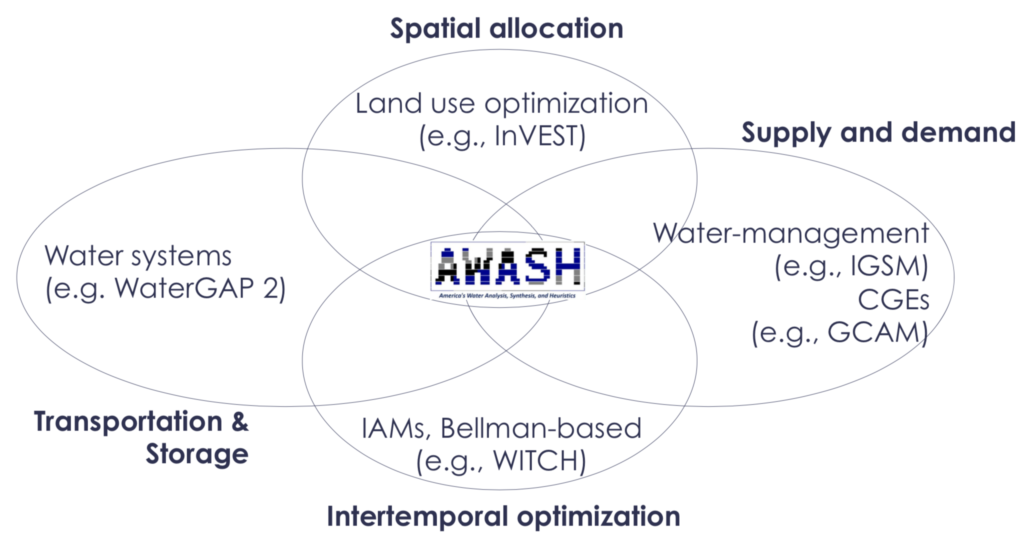
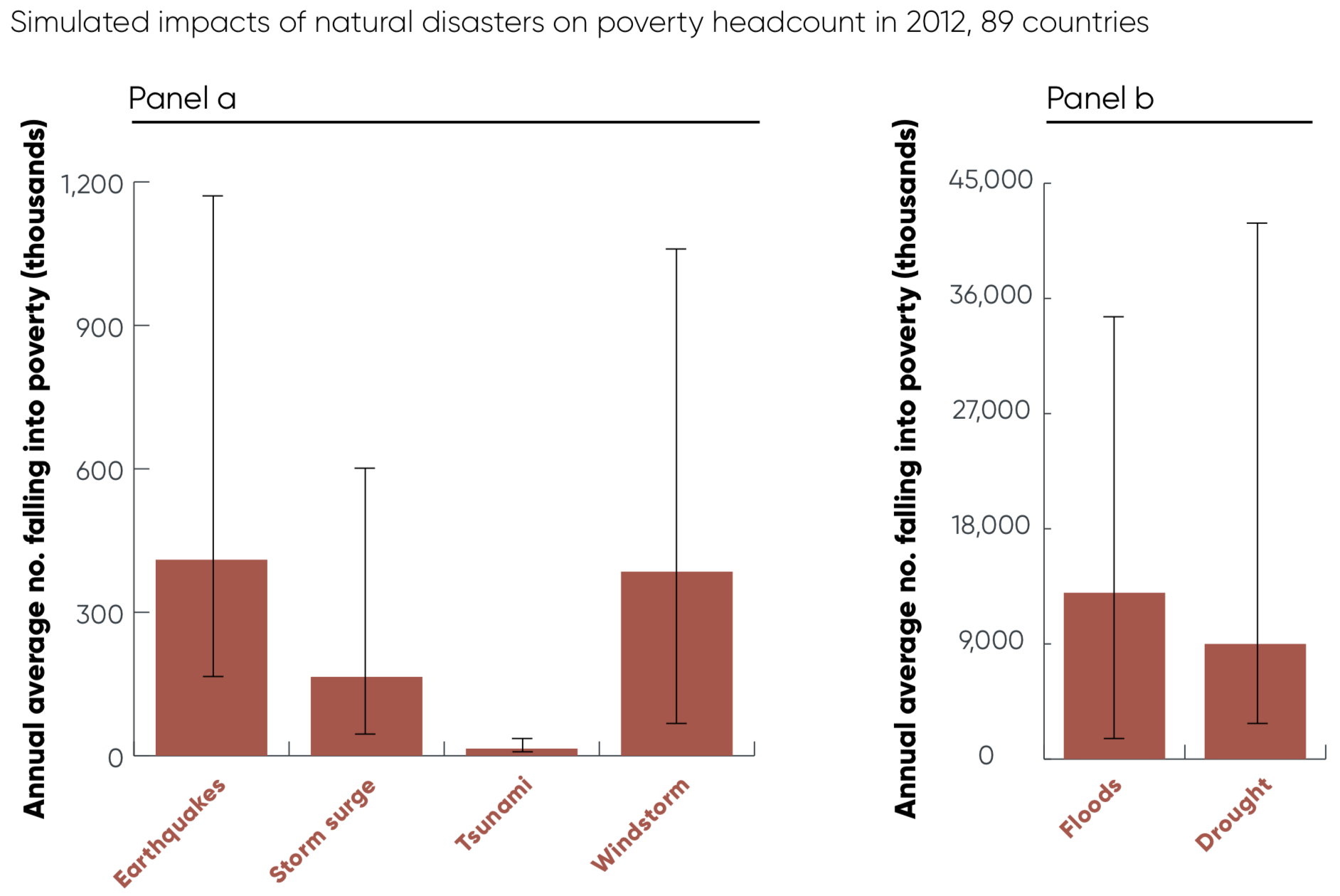
I wrote this up over the holidays, to feed into some discussions about the failings of integrated assessment models (IAMs). IAMs have long been the point at which climate science (in a simplistic form), economics (in a fanciful form), and policy (beyond what they deserve) meet. I’m a big believer in the potential of models to bring those three together, and the hard work of improving them will be a big part of my career (see also my EAERE newsletter piece). The point of this document is to highlight some progress that’s being made, and the next steps that are needed. Thanks to D. Anthoff and F. Moore for many of the citations.
Integrated assessment models fail to accurately represent the full risks of climate change. This document outlines the challenges (section 1), recent research and progress (section 2), and priorities to develop the next generation of IAMs.
1. Problems with the IAMs and existing challenges
The problems with IAMs have been extensively discussed elsewhere (Stern 2013, Pindyck 2017). The purpose here is to highlight those challenges that are responsive to changes in near-term research priorities. I think there are three categories: scientific deficiencies, tipping points and feedbacks, and disciplinary mismatches. The calibrations of the IAMs are often decades out of date (Rising 2018) and represent empirical methods which are no longer credible (e.g. Huber et al. 2017). The IAMs also miss the potential and consequences of catastrophic feedback in both the climate and social systems, and the corresponding long-tails of risk. Difficulties in communication between natural scientists, economists, and modelers have stalled the scientific process (see previous document, Juan-Carlos et al. WP).
2. Recent work to improve IAMs
Progress is being made on each of these three fronts. A new set of scientific standards represents the environmental economic consensus (Hsiang et al. 2017). The gap between empirical economics and IAMs has been bridged by, e.g., the works of the Climate Impact Lab, through empirically-estimated damage functions, with work on impacts on mortality, energy demand, agricultural production, labour productivity, and inter-group conflict (CIL 2018). Empirical estimates of the costs and potential of adaptation have also been developed (Carleton et al. 2018). Updated results have been integrated into IAMs for economic growth (Moore & Diaz 2015), agricultural productivity (Moore et al. 2017), and mortality (Vasquez WP), resulting in large SCC changes.
The natural science work on tipping points suggest some stylized results: multiple tipping points are already at risk of being triggered, and tipping points are interdependent, but known feedbacks are weak and may take centuries to unfold (O’Neill et al. 2017, Steffen et al. 2018, Kopp et al. 2016). Within IAMs, treatment of tipping points has been at the DICE-theory interface (Lemoine and Traeger 2016, Cai et al. 2016), and feedbacks through higher climate sensitivities (Ceronsky et al. 2005, Nordhaus 2018). Separately, there are feedbacks and tipping points in the economic systems, but only some of these have been studied: capital formation feedbacks (Houser et al. 2015), growth rate effects (Burke et al. 2015), and conflict feedbacks (Rising WP).
Interdisciplinary groups remain rare. The US National Academy of Sciences has produced suggestions on needed improvements, as part of the Social Cost of Carbon estimation process (NAS 2016). Resources For the Future is engaged in a multi-pronged project to implement these changes. This work is partly built upon the recent open-sourcing of RICE, PAGE, and FUND under a common modeling framework (Moore et al. 2018). The Climate Impact Lab is pioneering better connections between climate science and empirical economics. The ISIMIP process has improved standards for models, mainly in process models at the social-environment interface.
Since the development of the original IAMs, a wide variety of sector-specific impact, adaptation, and mitigation models have been developed (see ISIMIP), alternative IAMs (WITCH, REMIND, MERGE, GCAM, GIAM, ICAM), as well as integrated earth system models (MIT IGSM, IMAGE). The latter often include no mitigation, but mitigation is an area that I am not highlighting in this document, because of the longer research agenda needed. The IAM Consortium and Snowmass conferences are important points of contact across these models.
3. Priorities for new developments
Of the three challenges, I think that significant progress in improving the science within IAMs is occurring and the path forward is clear. The need to incorporate tipping points into IAMs is being undermined by (1) a lack of clear science, (2) difficulties in bridging the climate-economic-model cultures, and (3) methods of understanding long-term long-tail risks. Of these, (1) is being actively worked on the climate side, but clarity is not expected soon; economic tipping points need much more work. A process for (2) will require the repeated, collaboration-focused covening of researchers engaged in all aspects of the problem (see Bob Ward’s proposal). Concerning (3), the focus on cost-benefit analysis may poorly represent the relevant ethical choices, even under an accurate representation of tipping points, due to their long time horizon (under Ramsey discounting), and low probabilities. Alternatives are available (e.g., Watkiss & Downing 2008), but common norms are needed.
References:
Burke, M., Hsiang, S. M., & Miguel, E. (2015). Global non-linear effect of temperature on economic production. Nature, 527(7577), 235.
Cai, Y., Lenton, T. M., & Lontzek, T. S. (2016). Risk of multiple interacting tipping points should encourage rapid CO 2 emission reduction. Nature Climate Change, 6(5), 520.
Ceronsky, M., Anthoff, D., Hepburn, C., & Tol, R. S. (2005). Checking the price tag on catastrophe: the social cost of carbon under non-linear climate response. Climatic Change.
CIL (2018). Climate Impact Lab website: Our approach. Accessible at http://www.impactlab.org/our-approach/.
Houser, T., Hsiang, S., Kopp, R., & Larsen, K. (2015). Economic risks of climate change: an American prospectus. Columbia University Press.
Huber, V., Ibarreta, D., & Frieler, K. (2017). Cold-and heat-related mortality: a cautionary note on current damage functions with net benefits from climate change. Climatic change, 142(3-4), 407-418.
Kopp, R. E., Shwom, R. L., Wagner, G., & Yuan, J. (2016). Tipping elements and climate–economic shocks: Pathways toward integrated assessment. Earth’s Future, 4(8), 346-372.
Lemoine, D., & Traeger, C. P. (2016). Economics of tipping the climate dominoes. Nature Climate Change, 6(5), 514.
Moore, F. C., & Diaz, D. B. (2015). Temperature impacts on economic growth warrant stringent mitigation policy. Nature Climate Change, 5(2), 127.
Moore, F. C., Baldos, U., Hertel, T., & Diaz, D. (2017). New science of climate change impacts on agriculture implies higher social cost of carbon. Nature Communications, 8(1), 1607.
NAS (2016). Assessing Approaches to Updating the Social Cost of Carbon. Accessible at http://sites.nationalacademies.org/DBASSE/BECS/CurrentProjects/DBASSE_167526
Nordhaus, W. D. (2018). Global Melting? The Economics of Disintegration of the Greenland Ice Sheet (No. w24640). National Bureau of Economic Research.
O’Neill, B. C., Oppenheimer, M., Warren, R., Hallegatte, S., Kopp, R. E., Pörtner, H. O., … & Mach, K. J. (2017). IPCC reasons for concern regarding climate change risks. Nature Climate Change, 7(1), 28.
Pindyck, R. S. (2017). The use and misuse of models for climate policy. Review of Environmental Economics and Policy, 11(1), 100-114.
Rising, J. (2018). The Future Of The Cost Of Climate Change. EAERE Newsletter. Accessible at https://www.climateforesight.eu/global-policy/the-future-of-the-cost-of-climate-change/
Steffen, W., Rockström, J., Richardson, K., Lenton, T. M., Folke, C., Liverman, D., … & Donges, J. F. (2018). Trajectories of the Earth System in the Anthropocene. Proceedings of the National Academy of Sciences, 115(33), 8252-8259.
Stern, N. (2013). The structure of economic modeling of the potential impacts of climate change: grafting gross underestimation of risk onto already narrow science models. Journal of Economic Literature, 51(3), 838-59.
Vasquez, V. (WP). Uncertainty in Climate Impact Modelling: An Empirical Exploration of the Mortality Damage Function and Value of Statistical Life in FUND. Masters Dissertation.
Watkiss, P., & Downing, T. (2008). The social cost of carbon: Valuation estimates and their use in UK policy. Integrated Assessment, 8(1).